今年4月,Meta的AI模型Segment Anything Model(SAM,分割一切模型)发布,一键轻松实现图像分割,难怪网友直呼太强。
SAM模型之所以在计算机视觉领域产生重要影响,是因为图像分割是许多任务中的基础步骤,比如自动驾驶、人脸识别、车牌识别等都有用到。
在这些应用过程中,从目标检测、分割再到识别的整个流程,由算法自动完成,无需人工干预,而SAM模型正是专攻其中的图像分割。
虽然SAM是图像分割的代表性模型,但不可避免存在以下短板:
1.它能够处理图片分割,但是不能处理视频,尤其是不能对视频里边移动的物体做连续追踪。
2.它能分割,但是并不认识所分割的区域到底是什么。
3.它存在过度分割的问题,经常把一个完整的物体分割成不同的部分,而人是把目标作为整体看待的。
一、SAV模型
现在,云创数据(835305.BJ)在SAM和YOLOv8的基础上,“分割一切”模型的进化版——分割一切视频Segment-Any-Video(SAV)来了,进一步丰富了计算机视觉成果。
图片SAV模型(图片来源:SAV)
作为一种新的图像、视频分割方法,SAV可以在图片或视频中实现全自动标注,一键分割物体。
同时,基于Zero-Shot Transfer(零样本迁移),SAV无需额外训练,即使是训练库中没有的图片,也可以实现轻松分割。
与SAM相比,SAV升级主要表现在以下方面:
1.既可以分割图片,也可以分割视频;
2.可以明确目标对象并打标签;
3.可得到语义上完整的目标区域。

图片SAV与SAM图像分割对比结果(图片来源:SAV)
从上图可以看出,SAV将巴士、小汽车等分割成一个个完整的区域,而SAM是把这些单个的物体又分割为不同的区域。
除了图片以外,通过SAV,视频也可以进行清晰的目标分割和追踪。
二、示例
现在,我们在网页版 demo (http://sav.cstor.cn)上体验一下SAV,可以直观地感受SAM和SAV两者的差异。
在首页可任意选择一张示例图片,也可从本地上传图片,然后点击Segment按钮,就可以同时得到SAM和SAV的结果。

demo首页示例图片(图片来源:SAV)


图片分割结果:左侧为SAM,右侧为SAV(图片来源:SAV)
如果需要观察某个实例的详细效果,鼠标放置原图,移动鼠标即可。


图片移动鼠标查看详细分割效果(图片来源:SAV)
在上图中,由SAV分割的两只小狗是完整而独立的色块,并不像左边分割结果所展示——小狗耳朵颜色和身体部分颜色不一,不是完整的目标对象。同时,SAV分割的两只小狗都打上了“dog”的标签。
需要说明的是,本项目只关注算法自动分割的应用场景,所以SAV无需人工输入点、曲线、矩形框等提示信息。
更多示例如下:




图片图片分割结果对比(图片来源:SAV)
三、原理
如前所述, SAM的自动分割不返回标签信息,并且一个实例(例如,一辆车)可能会被拆分成多个小区域。

自动分割模式下,SAM不返回标签信息,车辆被分割成多个区域(图片来源:SAM)
基于此,研发团队在SAM的基础上加入YOLOv8检测模型,YOLOv8返回的结果中包含目标框、类别及置信度,目标框可作为提示信息输入到SAM,类别名称即为标签,因此SAM加YOLOv8可有效地解决上述问题。
该方法同样可用于视频分割任务,与处理单幅图像不同的是,除了分割,我们通常更关心目标的运动轨迹、目标重识别,以及如何实现一键抠视频等。因此研发团队在SAM和YOLOv8的基础上加入跟踪算法,持续关注感兴趣的目标,这样比单纯地分割每帧图像更有实际意义。
考虑到使用了目标检测模型,在跟踪方面,研发团队选择Tracking-By-Detection(TBD) 范式的跟踪方法,例如BoTSORT,而TBD是目前多目标跟踪任务中特别有效的范式。
图像分割
使用YOLOv8做前向推理,获得n个目标框,将这n个目标框作为提示信息输入到SAM模型并推理,即可完成目标框的实例分割并且得到n个对应的掩膜,然后对这n个掩膜取并集,结果记为m。

使用YOLOv8做前向推理(图片来源:SAV)
然后使用SAM做一次全局自动分割,将此时得到的掩膜图像记为m2。
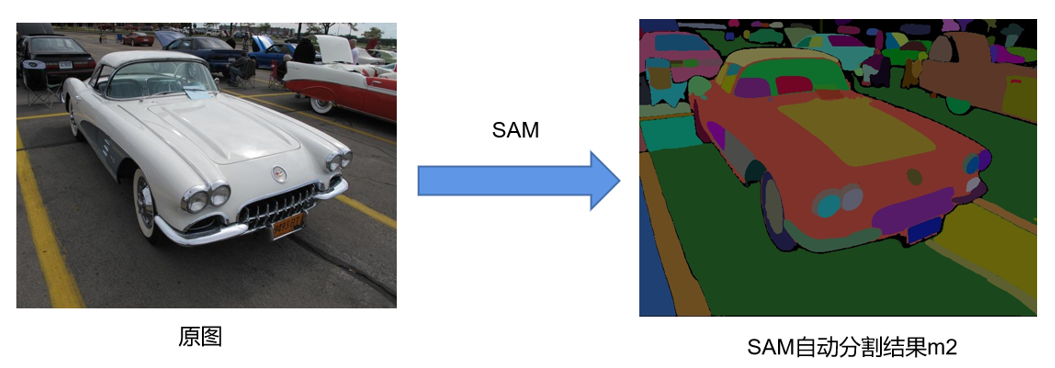
使用SAM做全局自动分割(图片来源:SAV)
由于YOLOv8无法检测到它不能识别的物体,可以设置两个超参数来确定新的物体,即未知区域与检测区域的交并比r,以及未知区域的像素个数n。具体而言,按面积对m2中的区域作降序排序,依次取出其中的区域,然后分别与m计算交并比,若交并比r小于0.3且该区域的像素个数n大于100,则认为该区域是一个新的物体。按照此方法处理m2中的所有区域,即可完成SAV分割单幅图像的全部流程。
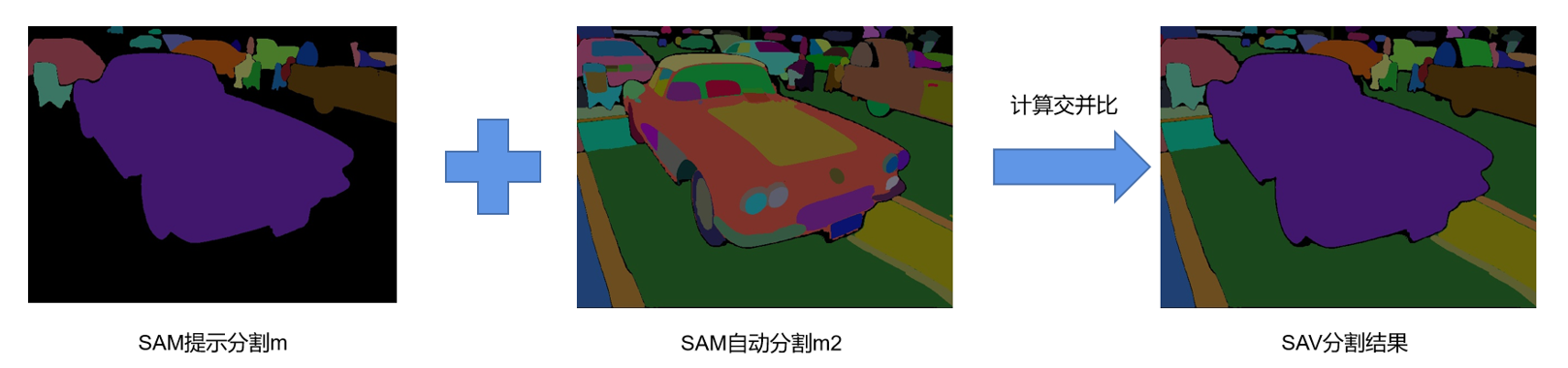
SAV分割单幅图像(图片来源:SAV)
视频分割
SAV视频分割的原理可以简单描述为:
1.使用YOLOv8检测某帧图像中的所有目标;
2.使用跟踪算法预测后续帧中的目标框;
3.根据检测到的目标框与当前轨迹集合相关联,获得每个目标的id;
4.将目标矩形框输入SAM,进行实例分割。
重复上述1~4步骤,实现视频分割。
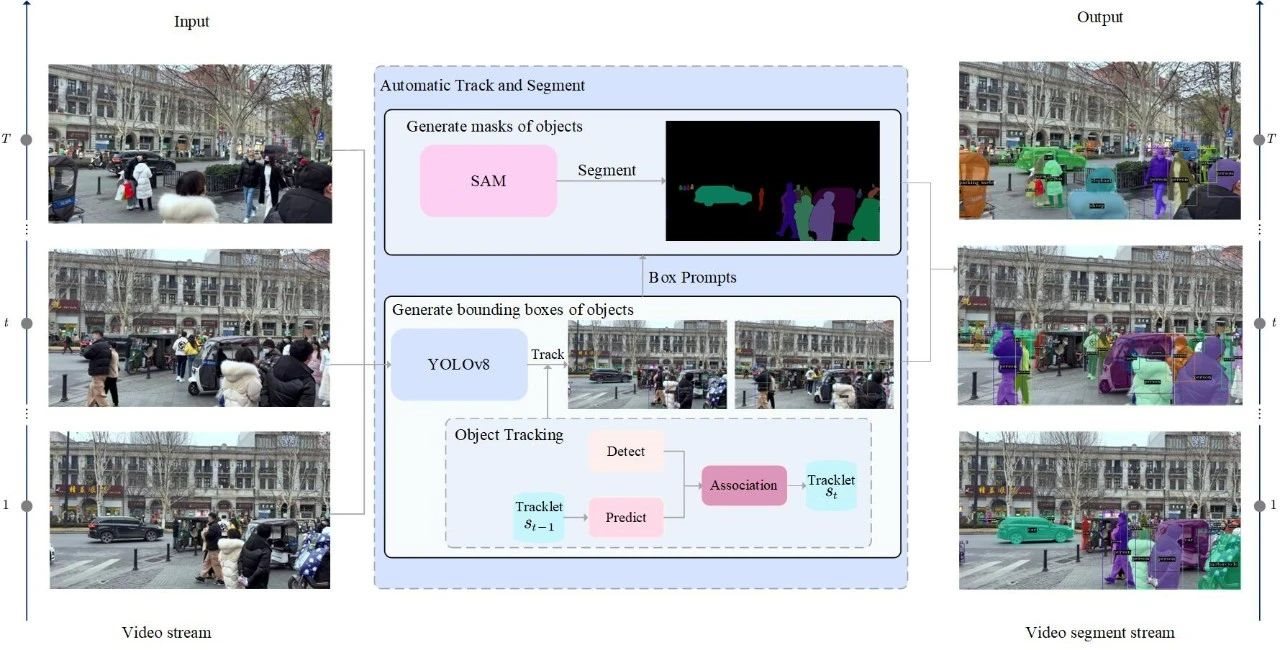
SAV视频分割算法框架图(图片来源:SAV)
效果展示
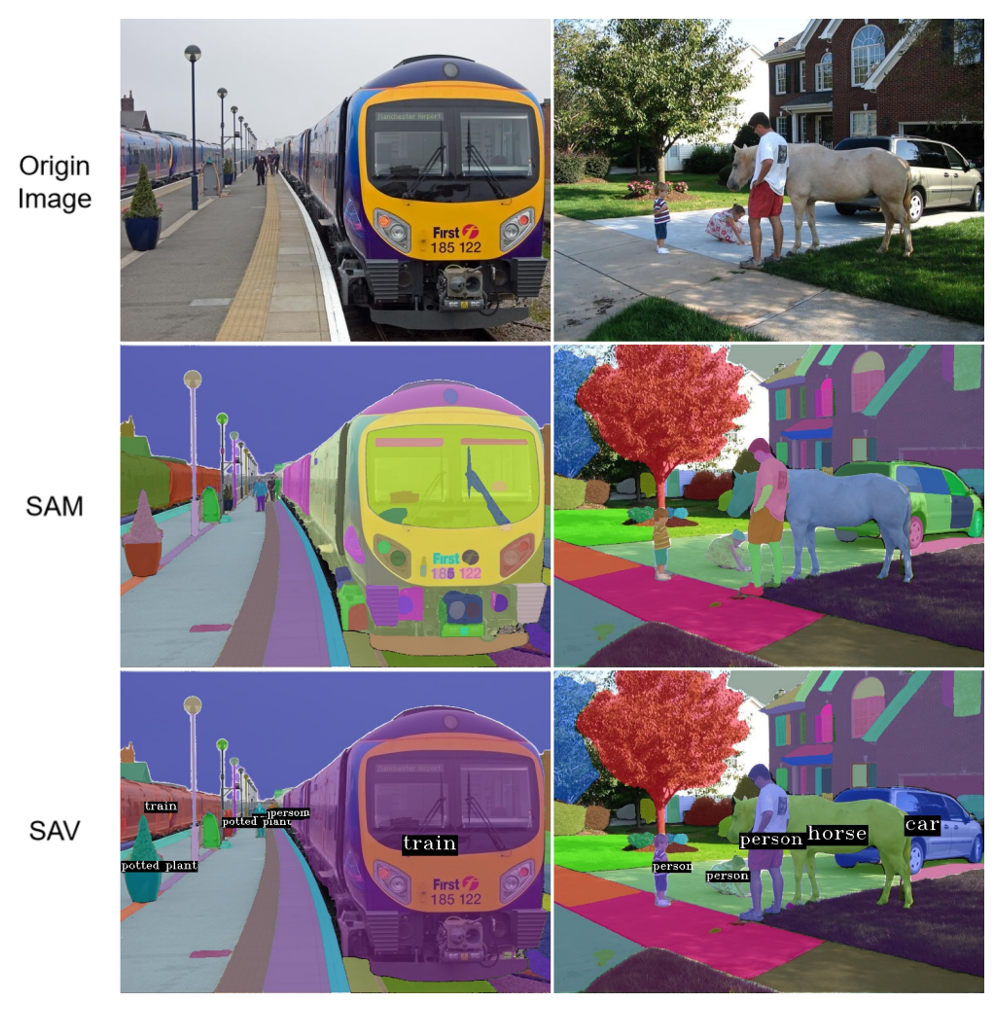
图像分割对比(图片来源:SAV)
可以看出,SAV能够很好地解决文章开头提到的SAM存在的问题。
四、潜在用途
无人驾驶。特斯拉无人驾驶汽车经常会把树桩或者墓碑当成行人,这个对于无人驾驶来说是不利的,因为如果是电线杆子在路边的话,我们没必要让无人驾驶汽车减速,但如果是一个行人准备过马路的话,那么就需要预先作出处理。SAV可以有效地解决这种问题。
无人机自主飞行。无人机自主飞行在密林中或者建筑物中,需要对所有的目标进行识别,并且做出恰当的反应。SAV将大大提高这种智能水平。
机器人视觉。机器人行走在工厂或者街上的时候,如果不认得障碍物,不认得道路,不认得其他移动的物体,那将寸步难行。SAV将为机器人装上智慧的眼睛。
重点区域防护。可连续追踪和识别每个目标,结合其他的算法对目标的身份和行为进行识别。确保重点区域的的每一个人,每一辆车都在管控的范围内。
五、更多
目前,SAV模型已开源,并在GitHub正式上线。感兴趣的朋友可以点击【阅读原文】或者直接前往https://github.com/cStor-cDeep/Segment-Any-Video了解,也欢迎向研发团队订制更高性能的大模型算法,联系方式如下:
联系人:张先生
邮箱:zhangkun@cstor.cn
手机:15895885574(微信同号)
参考文献
[1] Kirillov A, Mintun E, Ravi N, et al. Segment anything[J]. arXiv preprint arXiv:2304.02643, 2023.
[2] Dillon Reis, Jordan Kupec, et al. Real-Time Flying Object Detection with YOLOv8[J]. arXiv preprint arXiv:2305.09972, 2023.